Big Data and SupTech Development

In this blog post, I will explain how the process of collecting and processing supervisory data has been developing, what big data processing opportunities are offered by Azure Synapse Analytics and how the landscape of the supervisory technology or SupTech is evolving. At the end of the blog, I will also walk through the opportunities provided by the skilful use of big data in the FinTech area.
Supervisory data processing
One of the technological aspects in the financial sector supervision is the collection of data in file format. Prudential supervision reports are mostly prepared in XBRL format, as well as XML and CSV formats.
A large volume of data in the report files reduces the velocity/speed of data processing. Therefore, to transfer large data volumes, the CSV format is usually used as it does not contain much of the unnecessary technical content in addition to business data, actually merely separators of rows and columns. The European Banking Authority (EBA), as well as the FCMC are shifting from the XBRL format to the combined XBRL-CSV format for data collection, while maintaining the reporting data semantics and improving the velocity of the data processing.
The report processing usually involves the data validation. This requires repeated reading of the report content, for instance, for the validation of the data format, mandatory fields or formulas. Validation takes place faster if a file is beforehand loaded into the table of the SQL database and indexed. This is the traditional approach that works well if the data volume is relatively small.
The modern cloud computing technologies with the parallel processing capabilities allow to avoid data velocity challenges also in the caseof processing a massive volume of data, for instance, if the account statements of bank customers are to be processed for the purpose of monitoring the money laundering risks. As part of the SupTech strategy developed by the FCMC, we have experimented with these cloud computing technologies in our internal innovation laboratory and evaluated their use based on real data. We have explored the Azure cloud service for the purpose of big data processing and analytics. What were our findings?
Azure Synapse Analytics
When seeking for the big data processing opportunities, it is useful to look at those offered by Azure Synapse Analytics (formerly Azure SQL Data Warehouse). Azure Synapse Analytics currently combines the data warehouse, data integration and big data analytics functionality into a single platform, and is closely integrated with Power BI and Azure ML services11.
Chart 1. Components of Azure Synapse Analytics
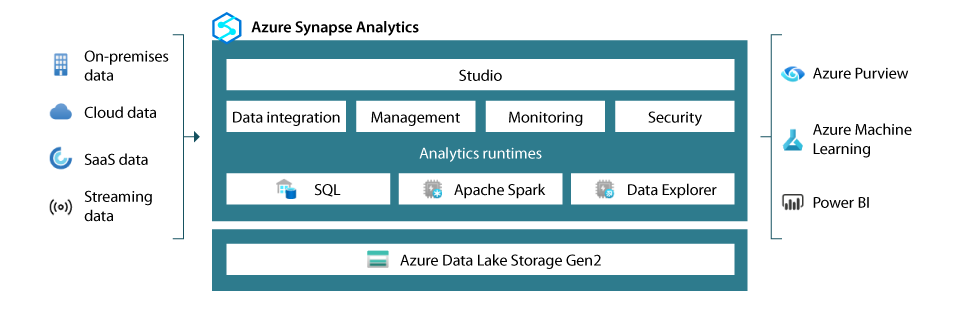
Source: What is Azure Synapse Analytics?
When using the T-SQL language that is well known to Microsoft SQL Server users, there are alternative ways of processing big data:
- Dedicated SQL Pool – the data from files is loaded into a database table, and queries ingest data from the table2.
- Serverless SQL Pool – the data file stored in a data lake is queried without the need to use a database1.
The Azure Synapse Analytics service has the same built-in data integration capabilities as those of Azure Data Factory service used separately for ETL (Extract, Transform, Load) purposes. As to ETL, it should be noted that with the PolyBase technology, Azure Synapse enables effective data processing in the ELT (Extract, Load, Transform) scenario3,4. Typically in data warehouses, data is extracted from a source system, then processed to meet the needs of analytics and loaded into dimension or fact tables. In the ELT process, data is extracted and loaded into the data warehouse before being further processed and adjusted to the needs of analytics. This is due to the advantages of Massive Parallel Processing (MPP). Unlike Symmetric Multi Processing (SMP) that is the most common type of data warehouse architectures where a processing task is done by multiple processors sharing a common operating system, the MPP task involves several instances of the operating systems10. It should be noted that PolyBase is a technology allowing access to data sources, for instance, large-scale data files stored in Azure Blob Storage or Azure Data Lake Storage.
When creating tables in the Azure Synapse data warehouse, the types Distributed or Replicated should be selected. The type Distributed is great for big tables6. The table data is distributed in similar portions by dividing them in rows on 60 computation nodes or individual devices with their own operating system and reserved resources. It is possible to perform the distribution in shards by usingHash or Round robin sharding patterns. The Hash sharding pattern is great for big fact tables where queries are performed according to data warehouses in a star schema. Round robin is a default type of distribution, with the Random function being used for data distribution.
Chart 2. Data hash distribution by using the Hash function method
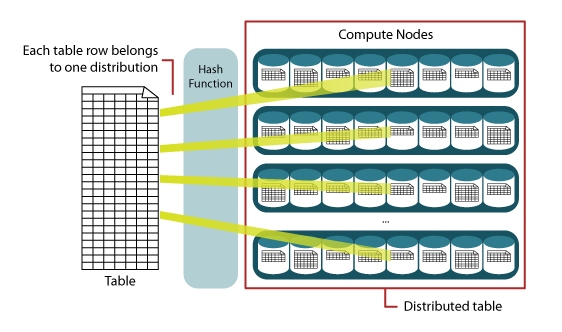
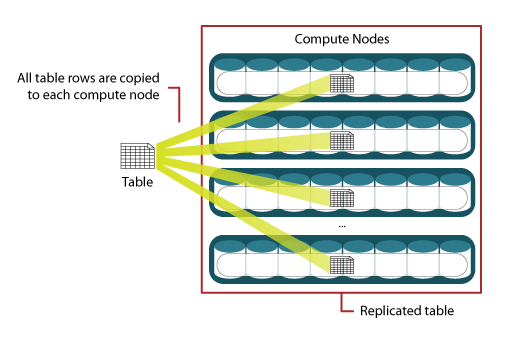
Replicated tables are best suited for small dimension tables with less than 2 GB storage. This type of table is not distributed in parts, but its copy is cached on each of the computation nodes. Typically, this pattern is intended to be used for dimension tables to speed up the process of joining data from the corresponding records of the fact and dimension tables; this is done locally within each computation node.
Chart 3. Data replication
The big data processing in Azure environment can be also performed via U-SQL (its full name is Unified-SQL) that combines SQL with C#7. It is intended to be used for data processing when reading files, performing transformation and exporting in simplified formats. Unfortunately, this technology is retiring. The language has been primarily used by Azure Data Lake Analytics Gen1. Azure Data Lake Storage Gen1 retirement will be in February 2024. Azure Data Lake Analytics Gen2 has a differentarchitecture, and it does not support U-SQL. Azure customers are encouraged to recode U-SQL scripts into languages supported by Apache Spark, for instance, Phyton, in order to continue to operate the automated processes in the new service or to migrate them to the Azure Synapse Analytics service8.
SupTech evolution
As it is stated in the OECD annual publication "OECD Business and Finance Outlook 2021" with SupTech being one of the discussed topics, the SupTech initiatives may be classified as belonging to four successive technological layers or "generations", which respectively generate descriptive, diagnostic, predictive and prescriptive analytics9.
The first generation (descriptive analytics) describes the situation, for example, 20 years ago, when the FCMC had a data collecting channel in place; however, most of the reports were submitted in paper form or in an unstructured way, and the overall volume of data was very small. Currently, the situation is different.
Chart 4. The four generations of SupTech
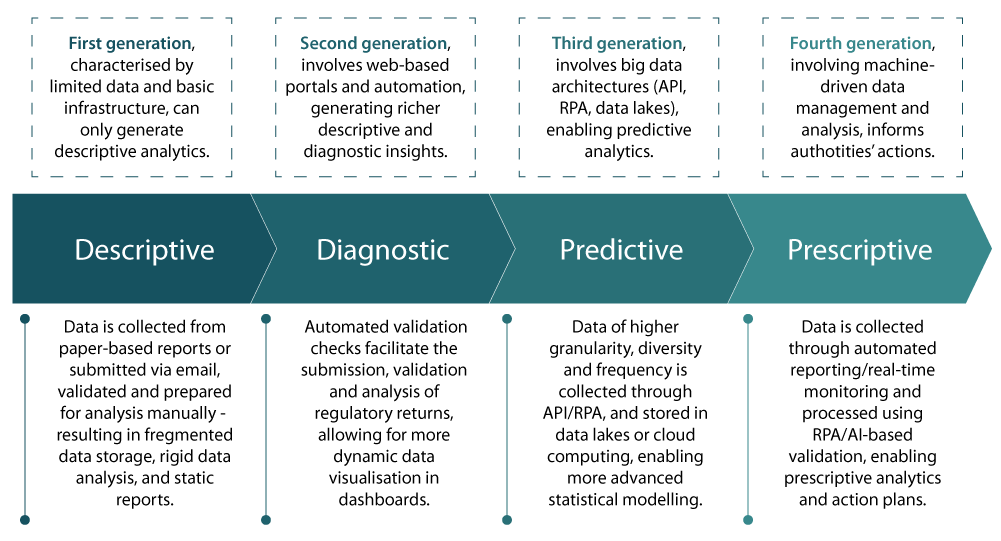
The second generation (diagnostic analytics) describes the previous decade even before the introduction of the cloud computing technologies when the FCMC collected most part of supervisory information by way of processing automated and structured reports.
The growing amount of data and the limited server resources urged the FCMC to move towards the third generation or the predictive analytics. To move forward, including towards the fourth generation (prescriptive analytics), it is necessary to strengthen competence and expertise within an organisation in the area of forecasting modelling and artificial intelligence technologies, without losing the focus on the development of analytics, inter alia, Network Analysis.
The OECD publication has quoted a survey from the Financial Stability Board (FSB) undertaken among FSB members regarding the use of data analysis. According to the survey, 49% of the surveyed authorities are using data analysis functions for descriptive outputs and 32% for diagnostic outputs. Only a minority of respondents report using SupTech technologies comprised in the third predictive category (11%), and the fourth prescriptive category (8%).
The Azure Synapse Analytics service may serve as a basis for the adjustment of the infrastructure to the big data processing. The closely integrated services such as Azure ML may offer possibilities to create forecasting models and automate the process of applying them.
The use of Azure Synapse has two great benefits. The service enables processing of big reporting data files with a great capacity and accelerating the operation of the analytics solutions, while enhancing the performance of data warehousing queries.
Big data and FinTech
SupTech refers to the use of the technologies for the supervision of the financial service providers, including FinTech. Big data along with artificial intelligence and blockchains are the main technologies supporting the development of FinTech services12. In other words, the use of technologies in the supervisory sector is more important than their application in supervision. The amount of data used in the provision of FinTech services, for instance, the one generated by the mobile application users, is so large that it is not possible to process them with previously used methods.
There is a relatively wide spectrum of services requiring the use of big data14,15. For instance, big data and machine learning based analytics have already been used in the industry for security and fraud detection purposes for quite a while. The more recent trend in online payments is the merger of payment processing with POS (point of sale) lending mechanisms that enable users to get loans right at checkout.
Modern insurance companies take full advantage of big data and actively use machine learning to create highly customized, low-risk insurance offers that address the specific needs of particular categories of users.
Big data and artificial intelligence models are widely used in microfinancing and other types of lending businesses to reduce the cost of credit underwriting and make loans available to a wider audience that often has a challenged credit history.
Chart 5. The range of services involving big data
Securities trading is becoming increasingly complex with cryptocurrencies and crypto-derivatives being thrown into the mix. This industry has long relied on data science, and this synergy will continue to evolve as the amount of data processed by trading platforms grows and the reaction time becomes a vital factor, especially in large-volume trading in highly volatile markets.
Along with FinTech, the traditional bank services also involve the modern data processing technologies. Big data help address, for instance, the following tasks13:
- analysis of customers' incomes and expenditures;
- segmentation of the customer base;
- risk assessment and fraud prevention;
- enhancing customer loyalty.
The financial sector strongly relies on the big data technologies. Without them, many services would not be available or would be of lower quality, less accessible and less beneficial. The story is similar to the supervision of the financial sector. The growing amount of data collected for the purpose of supervision and granularity require supervisory authorities to use the big data technologies in their work.
Sources used:
- Analyze data with a serverless SQL pool
- Analyze data with dedicated SQL pools
- Data loading strategies for dedicated SQL pool in Azure Synapse Analytics
- Design a PolyBase data loading strategy for dedicated SQL pool in Azure Synapse Analytics
- Design guidance for using replicated tables in Synapse SQL pool
- Guidance for designing distributed tables using dedicated SQL pool in Azure Synapse Analytics
- Introducing U-SQL – A Language that makes Big Data Processing Easy
- Migrate Azure Data Lake Analytics to Azure Synapse Analytics
- The use of SupTech to enhance market supervision and integrity
- Transitioning from SMP to MPP, the why and the how
- What is Azure Synapse Analytics?
- The role of Big Data in the 2020’s fintech revolution
- The Role of Big Data in Banking : How do Modern Banks Use Big Data?
- Big Data in Fintech: Benefits for Financial Industry
- Joint Committee Discussion Paper on the Use of Big Data by Financial Institutions