Lielie dati un SupTech attīstība

Šajā blogā skaidrošu, kā attīstījusies uzraudzības datu vākšana un apstrāde, kādas lielapjoma datu apstrādes iespējas piedāvā Azure Synapse Analytics un kā attīstās uzraudzības tehnoloģiju jeb SupTech joma. Bloga noslēgumā arī ieskats, kādas iespējas FinTech jomā sniedz lielo datu prasmīga izmantošana.
Uzraudzības datu apstrāde
Viens no tehnoloģiskiem aspektiem finanšu sektora uzraudzībā ir datu vākšana failu veidā. Prudenciālās uzraudzības pārskatiem pamatā tiek pielietots XBRL formāts, kā arī XML un CSV formāti.
Liels datu apjoms pārskatu failos samazina datu apstrādes ātrdarbību. Tādējādi liela apjoma datu pārnesei parasti tiek lietots CSV formāts tādēļ, ka šādā formātā ir maz lieka tehniskā satura papildu biznesa datiem, faktiski tikai rindu un kolonnu atdalītāji. Eiropas Banku iestāde (European Banking Authority, EBA), kā arī FKTK datu vākšanā pāriet no XBRL formāta uz kombinētu XBRL-CSV formātu, saglabājot gan pārskatu datu semantiku, gan arī uzlabojot datu apstrādes ātrdarbību.
Pārskatu apstrādē parasti veic datu validēšanu. Tam nepieciešams vairākkārt nolasīt pārskata saturu, piem., datu formāta, obligāto lauku vai formulu validēšanai. Validēšana notiek ātrāk, ja failu pirms tam ielādē SQL datubāzes tabulā un noindeksē. Šāda ir tradicionālā pieeja, un tā lieliski darbojas pie salīdzinoši nelieliem datu apjomiem.
Mūsdienu mākoņdatošanas tehnoloģijas ar paralēlās procesēšanas iespējām ļauj paglābties no ātrdarbības problēmām arī ļoti lielu apstrādājamo datu apjomu gadījumos, piem., ja jāapstrādā banku klientu kontu izraksti naudas atmazgāšanas risku uzraudzībai. Realizējot FKTK SupTech stratēģiju, FKTK Inovāciju laboratorijā esam izmēģinājuši šīs mākoņdatošanas tehnoloģijas un novērtējuši to darbību ar reāliem datiem. Esam pētījuši Azure mākoņservisu lielo datu apstrādei un analītikai. Kādi bija mūsu atklājumi?
Azure Synapse Analytics
Lūkojoties pēc lielapjoma datu apstrādes iespējām, ir lietderīgi paraudzīties uz Azure Synapse Analytics iespējām. Tas ir jaunu veidolu ieguvis iepriekš zināmais Azure SQL Data Warehouse. Šobrīd tas apvieno datu noliktavu, datu integrācijas un lielo datu analītikas funkcionalitāti, kā arī cieši integrējas ar Power BI un Azure ML servisiem11.
1. attēls. Azure Synapse Analytics servisa uzbūve
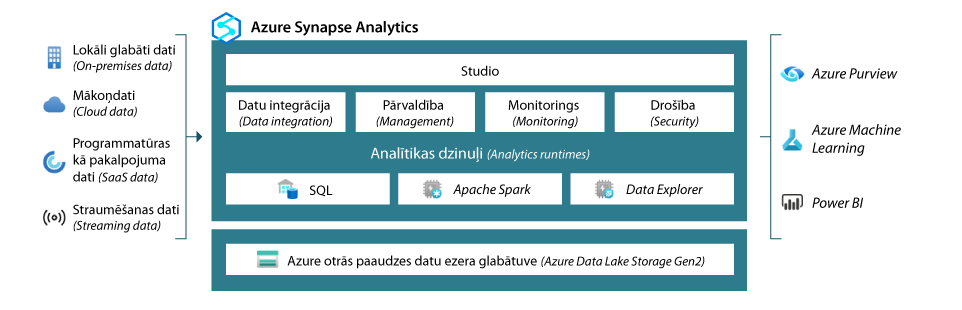
Lielo datu apstrādei, pielietojot valodu T-SQL, kas labi zināma Microsoft SQL Server cienītājiem, ir pieejamas alternatīvas:
- Dedicated SQL Pool – dati no failiem tiek ielādēti datubāzes tabulā, vaicājumi pārmeklē tabulu2.
- Serverless SQL Pool – vaicājumi tiek izpildīti datu failam, kas tiek glabāts datu ezerā, neiesaistot datubāzi1.
Azure Synapse Analytics servisā ir iebūvētas tādas pat datu integrācijas iespējas, kādas ir atsevišķi ETL (Extract Transform Load) mērķiem paredzētam Azure Data Factory servisam. Saistībā ar ETL jāatzīmē, ka Azure Synapse ar PolyBase tehnoloģiju padara efektīvu datu apstrādi ELT (Extract Load Transform) scenārijā3,4. Datu noliktavās ierasts, ka dati tiek izgūti no avotiem, apstrādāti atbilstoši analītikas nepieciešamībai un ielādēti dimensiju vai faktu tabulās. ELT procesā dati tiek atlasīti un ielādēti datu noliktavā pirms to tālākas apstrādes un pielāgošanas analītikas vajadzībām. Tas ir masveida paralēlās procesēšanas (Massive Parallel Processing, MPP) priekšrocību dēļ. Pretstatā simetriskai daudzapstrādei (Symetric Multi Processing, SMP), kas dominē ierastās datu noliktavu arhitektūrās, kur apstrādes uzdevums tiek izpildīts uz vairākiem procesoriem, taču uz vienas operētājsistēmas, MPP uzdevuma izpildē iesaista vairākas operētājsistēmu instances10. Jāpiebilst, ka PolyBase ir tehnoloģija, kas ļauj ar T-SQL izteiksmēm piekļūt datu avotiem, piem., lielapjoma datu failiem, kas glabājas Azure Blob Storage vai Azure Data Lake Storage.
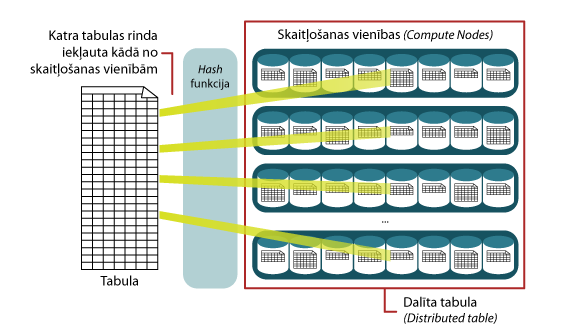
Definējot tabulas Azure Synapse datu noliktavā, jāizvēlas veids Distributed vai Replicated. Liela izmēra tabulām paredzēts izvēlēties veidu Distributed6. Tabulas dati tiek izdalīti līdzīgās porcijās, dalot rindās uz 60 procesēšanas vienībām (Computation nodes) jeb atsevišķām mašīnām ar savu operētājsistēmu un rezervētiem resursiem. Porciju sadalījumu iespējams realizēt Hash vai Round robin variantā. Hash funkcijas sadalījums piemērots lielām faktu tabulām, kur vaicājumi tiek realizēti atbilstoši datu noliktavām zvaigznes shēmas modelī. Round robin ir noklusētais veids, datu sadalīšanai tiek pielietota Random funkcija.
2. attēls. Datu dalītā izvietošana, pielietojot Hash funkcijas metodi
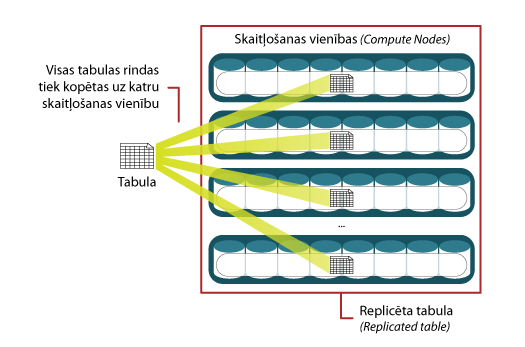
Replicated veida tabulas paredzēts pielietot maza izmēra tabulām, ieteicams līdz diviem gigabaitiem7. Šī veida tabulas netiek dalītas porcijās, bet gan tiek izvietota tās kopija katrā no procesēšanas vienībām. Tipiski tās paredzēts izmantot dimensiju tabulām, lai paātrinātu datu sasaisti starp faktu un dimensiju tabulu atbilstošiem ierakstiem, to realizējot lokāli katras procesēšanas vienības ietvaros.
3. attēls. Datu replicēšana
Lielapjoma datu apstrādei Azure vidē ir pieejama arī U-SQL, pilnā nosaukumā Unified-SQL, kas ir SQL un C# valodu apvienojums7. Paredzēta datu apstrādei, nolasot failus, veicot transformāciju un eksportēšanu vienkāršas uzbūves izteiksmju veidā. Diemžēl aizejoša tehnoloģija. Šī valoda izmantota pamatā Azure Data Lake Analytics pirmās paaudzes servisā. 2024. gada februārī paredzēta servisa darbības pārtraukšana. Otrās paaudzes servisam ir cita uzbūve, un U-SQL tajā netiek atbalstīta. Azure klienti tiek mudināti U-SQL skriptus pārkodēt Apache Spark dzinuļa atbalstītās valodās, piem., Phyton, lai turpinātu automatizētos procesus darbināt jaunajā servisā, vai migrēt uz Azure Synapse Analytics servisu8.
SupTech jomas attīstība
SupTech attīstības ceļu raksturo vairāki posmi – aprakstošais, diagnosticējošais, prediktīvais un preskriptīvais, lasāms Ekonomikas sadarbības un attīstības organizācijas (OECD) gadskārtējā publikācijā "OECD Business and Finance Outlook 2021", kurā viena no aplūkotajām tēmām ir SupTech9.
Aprakstošā fāze raksturo situāciju, piem., FKTK pirms 20 gadiem, kad pārskatu datu vākšanai bija izveidots iesūtīšanas kanāls, taču vairums pārskatu tika iesniegti formu jeb nestrukturētā veidā un kopumā datu apjoms bija ļoti neliels. Šobrīd situācija jau ir citāda.
4. attēls. SupTech attīstības četri posmi
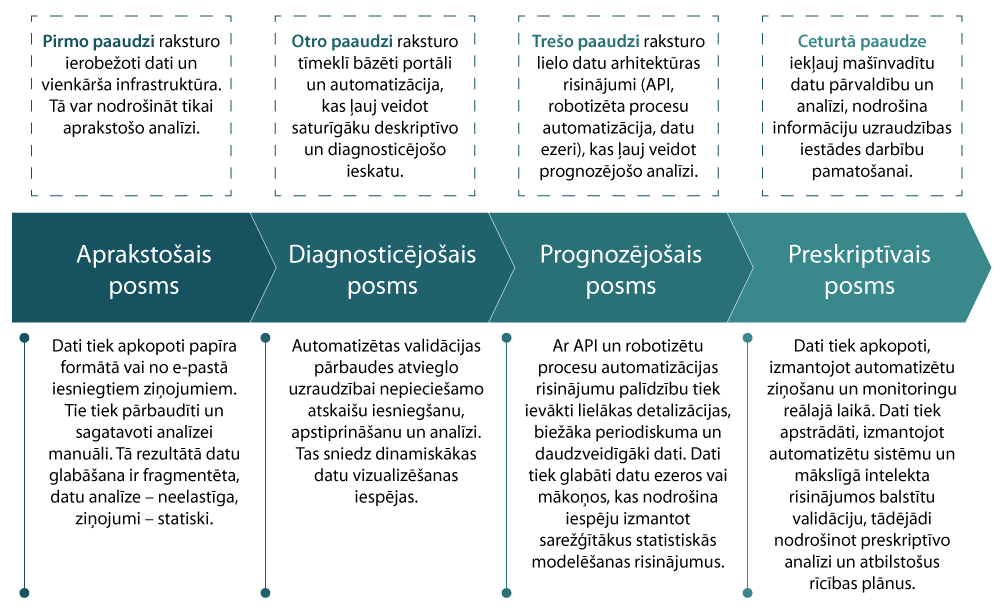
Diagnosticējošā fāze atbilst tam, kas FKTK realizēts iepriekšējā desmitgadē vēl pirms mākoņdatošanas tehnoloģiju ieviešanas, proti, lielākā daļa uzraudzības informācijas tiek ievākta ar automatizētu, strukturētu pārskatu apstrādi.
Pieaugošs datu apjoms, ierobežotie serveru resursi liek spert soli 3. jeb prognozējošās fāzes virzienā. Lai virzītos tālāk, t.sk. uz preskriptīvo fāzi, nepieciešams veidot organizācijas kompetenci un briedumu prognozējošās modelēšanas un mākslīgā intelekta tehnoloģiju virzienā, neaizmirstot par attīstību analītikas, t.sk. Network Analysis virzienā.
OECD publikācijā citēta Finanšu stabilitātes padomes (Financial Stability Board) veikta tās dalībinstitūciju aptauja par datu analīzes izmantošanu. Šīs aptaujas rezultāti atklāj, ka 49% aptaujāto organizāciju izmanto datu analīzi aprakstošiem mērķiem, 32% – diagnosticējošiem. Visai neliela daļa jeb 11% datu analīzē pielieto prognozējošas SupTech tehnoloģijas, un 8% lieto preskriptīvās fāzes tehnoloģijas⁹.
Azure Synapse Analytics serviss var kalpot kā bāze infrastruktūras pielāgošanai lielo datu apstrādei. Ar to cieši integrētie servisi, piem., Azure ML var sniegt iespējas veidot prognozēšanas modeļus un automatizēt to pielietošanu.
Azure Synapse pielietošanā saskatāmi divi lieli ieguvumi. Serviss ļauj ar lielu jaudu apstrādāt liela izmēra pārskatu datu failus, kā arī paātrināt analītikas risinājumu darbību, uzlabojot datu noliktavas vaicājumu veiktspēju.
Lielie dati un FinTech joma
SupTech ir tehnoloģijas finanšu pakalpojumu sniedzēju, t.sk. FinTech uzraudzībai. Lielie dati līdzās mākslīgajam intelektam un blokķēdēm ir galvenās FinTech pakalpojumu attīstību veicinošās tehnoloģijas12. Citiem vārdiem, uzraugāmajā sektorā tehnoloģiju pielietošanas nozīme ir vēl lielāka, nekā to pielietošana uzraudzībā. FinTech pakalpojumu sniegšanā pielietotais datu apjoms, piem., tas, ko rada mobilās aplikācijas lietotāji, ir tik liels, ka to apstrāde ar agrāk ierastām metodēm nav iespējama.
Ir gana plašs pakalpojumu spektrs, kur nepieciešams lielo datu pielietojums14,15. Piem., lielie dati un uz mašīnmācīšanos balstīta analītika jau ilgu laiku tiek izmantota tiešsaistes maksājumu drošības un krāpšanas atklāšanas nolūkos. Jaunākā tendence ir maksājumu apstrādes apvienošana ar POS (Point of sale) kreditēšanas mehānismiem, kas ļauj lietotājiem saņemt aizdevumus tieši norēķināšanās brīdī.
Mūsdienu apdrošināšanas kompānijas izmanto lielo datu priekšrocības un aktīvi pielieto mašīnmācīšanos, lai izveidotu īpaši pielāgotus, zema riska apdrošināšanas piedāvājumus, kas atbilst noteiktu lietotāju kategoriju specifiskajām vajadzībām.
Lielie dati un mākslīgā intelekta modeļi tiek plaši izmantoti mikrofinansēšanas un cita veida kreditēšanas uzņēmumos, lai samazinātu kredīta parakstīšanas izmaksas un padarītu aizdevumus pieejamus plašākai auditorijai, kuras vidū ir arī cilvēki ar negatīvu kredītvēsturi.
5. attēls. Pakalpojumu klāsts, kur pielietojami lielie dati
Vērtspapīru tirdzniecība kļūst arvien sarežģītāka, tiek iesaistītas kriptovalūtas un kriptoatvasinātie instrumenti. Šī nozare jau sen ir balstījusies uz datu zinātni, un šī sinerģija turpinās attīstīties, pieaugot tirdzniecības platformu apstrādāto datu apjomam un reakcijas laikam kļūstot par būtisku faktoru, jo īpaši liela apjoma tirdzniecībā ļoti nepastāvīgos tirgos.
Līdztekus FinTech arī tradicionālajos banku pakalpojumos tiek iesaistītas modernās datu apstrādes tehnoloģijas. Lielie dati palīdz risināt, piem., šādus uzdevumus13:
- klientu ienākumu/izdevumu analīze;
- klientu bāzes segmentēšana;
- risku vērtēšana un draudu novēršana;
- klientu lojalitātes celšana.
Finanšu nozare ir ļoti atkarīga no lielo datu tehnoloģijām. Bez tām daudzi pakalpojumi nebūtu pieejami vai būtu nekvalitatīvāki, nepieejamāki un neizdevīgāki. Līdzīgi ir arī ar finanšu nozares uzraudzību. Pieaugošs uzraudzības veikšanai vākto datu apjoms un granularitāte rada nepieciešamību uzrauga darbā pielietot lielo datu tehnoloģijas.
Izmantotie avoti
- Analyze data with a serverless SQL pool
- Analyze data with dedicated SQL pools
- Data loading strategies for dedicated SQL pool in Azure Synapse Analytics
- Design a PolyBase data loading strategy for dedicated SQL pool in Azure Synapse Analytics
- Design guidance for using replicated tables in Synapse SQL pool
- Guidance for designing distributed tables using dedicated SQL pool in Azure Synapse Analytics
- Introducing U-SQL – A Language that makes Big Data Processing Easy
- Migrate Azure Data Lake Analytics to Azure Synapse Analytics
- The use of SupTech to enhance market supervision and integrity
- Transitioning from SMP to MPP, the why and the how
- What is Azure Synapse Analytics?
- The role of Big Data in the 2020’s fintech revolution
- The Role of Big Data in Banking : How do Modern Banks Use Big Data?
- Big Data in Fintech: Benefits for Financial Industry
- Joint Committee Discussion Paper on the Use of Big Data by Financial Institutions